






摘要:,,在2024年的视角,FlinkSpark实时计算的优势在于其高吞吐量和低延迟的特性,适用于处理大规模数据流。面临的挑战包括数据处理复杂性增加、资源管理和性能优化等。至2024年12月18日实时计算领域,FlinkSpark的应用和发展趋势持续受到关注。
随着大数据技术的不断革新,实时计算成为数据处理领域的核心焦点,FlinkSpark作为当前流行的实时计算框架,其在处理海量数据、确保数据实时性和计算效率方面展现出了显著优势,本文将围绕“2024年12月18日实时计算FlinkSpark”展开讨论,旨在分析FlinkSpark的优缺点,阐述个人立场,并探讨未来可能的发展趋势。
一、FlinkSpark实时计算的优势分析:
1、高性能的流处理: FlinkSpark结合了Apache Flink的流处理能力和Apache Spark的批处理能力,能够在面对实时数据流时保持高吞吐量和低延迟,这使得在处理大规模实时数据时可以保证数据的实时性和计算的准确性。
2、灵活的编程模型: FlinkSpark提供了高级的抽象和编程模型,允许开发者以声明式的方式编写程序,简化了复杂数据处理逻辑的编写和维护,它支持多种编程语言,为开发者提供了更大的灵活性。
3、强大的容错性和扩展性: FlinkSpark具备高容错性和强大的扩展能力,其分布式架构可以处理节点失败和数据丢失的情况,保证了系统的稳定性和数据的可靠性,它支持在集群上水平扩展,能够应对不断增长的数据量和计算需求。

4、丰富的生态系统和集成能力: 作为开源生态系统的一部分,FlinkSpark能够与其他大数据工具和框架无缝集成,如Hadoop、Kafka、MQTT等,这使得在构建大数据解决方案时具有更大的灵活性和选择空间。
二、FlinkSpark实时计算的挑战与问题:
1、资源管理和优化: 在大规模集群上运行FlinkSpark时,资源管理和优化变得至关重要,如何合理分配资源、避免资源浪费和提高资源利用率是面临的主要挑战之一。
2、复杂场景下的性能瓶颈: 尽管FlinkSpark在处理大部分实时计算场景时表现出色,但在面对某些复杂计算场景时,可能会遇到性能瓶颈,处理复杂算法和关联分析时,需要更高的计算能力和优化策略。
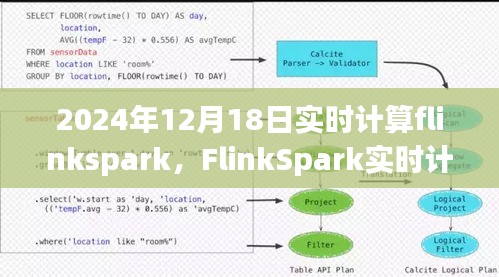
3、数据安全和隐私保护: 在处理大量实时数据时,数据安全和隐私保护成为不可忽视的问题,如何确保数据的安全传输、存储和使用是FlinkSpark需要解决的重要问题。
4、技术更新与人才培养: 随着技术的不断发展,FlinkSpark也需要不断更新以适应新的需求和挑战,培养具备实时计算技能的人才也是推动技术发展的关键。
三、个人立场及理由:
我认为FlinkSpark在实时计算领域具有巨大的潜力,其高性能的流处理能力、灵活的编程模型以及强大的容错性和扩展能力使其成为构建大数据解决方案的理想选择,我们也应该看到其面临的挑战和问题,如资源管理和优化、复杂场景下的性能瓶颈等,我们应该持续关注并研究这些问题,推动FlinkSpark技术的不断进步,加强人才培养和技术交流也是推动技术发展的关键。

FlinkSpark作为实时计算领域的领先框架,在大数据处理中展现出了显著优势,随着技术的不断发展,其将面临新的挑战和问题,我们应该持续关注这些问题,加强研究和人才培养,推动FlinkSpark的进步和发展,FlinkSpark将在实时计算领域发挥更大的作用,为大数据处理提供更高效、更灵活的解决方案。
转载请注明来自1608手游,本文标题:《2024年视角下的FlinkSpark实时计算,优势与挑战解析》
 冀ICP备2023036363号-1
冀ICP备2023036363号-1
还没有评论,来说两句吧...